
We looked at the first aggregate rule of thumb in the previous article about Domain-Driven Design aggregates. What I didn’t cover was how to deal with collaborative domains. One way to deal with issues that appear in collaborative domains is to use optimistic concurrency.
Recap
We looked at using an aggregate to model our consistency boundaries. In particular, we were creating boundaries around applying changes to a time-sheet in a time-tracking application.
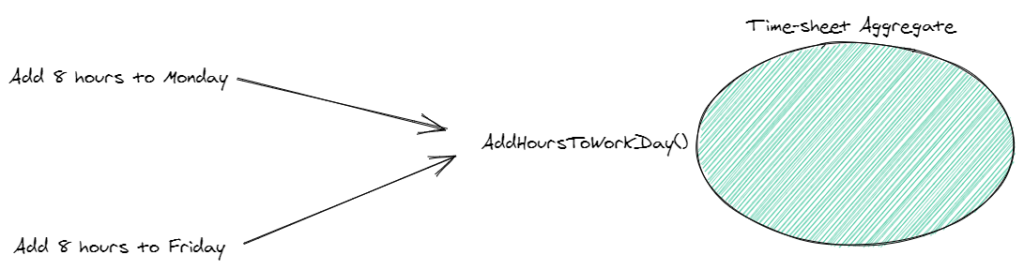
This approach helps us to better reason about and manage our important business rules related to the time-sheet business concept. All other parts of our system have to come through the time-sheet aggregate – just like a gateway.
However, this still doesn’t solve the issue where two concurrent operations on the aggregate – that logically should fail – will both succeed.
Collaborative Domains
Collaborative domains (i.e. domains where resources can be changed by multiple users/clients at the same time) call for more intelligent handling of our business logic.
In our case, we have two operations that are trying to add 8 hours to the time sheet. The time sheet is currently at 32 worked hours and should not go over 40 hours (that’s a hard business rule).
So, only one of the two operations should succeed. But, given the standard implementation, they will both succeed.
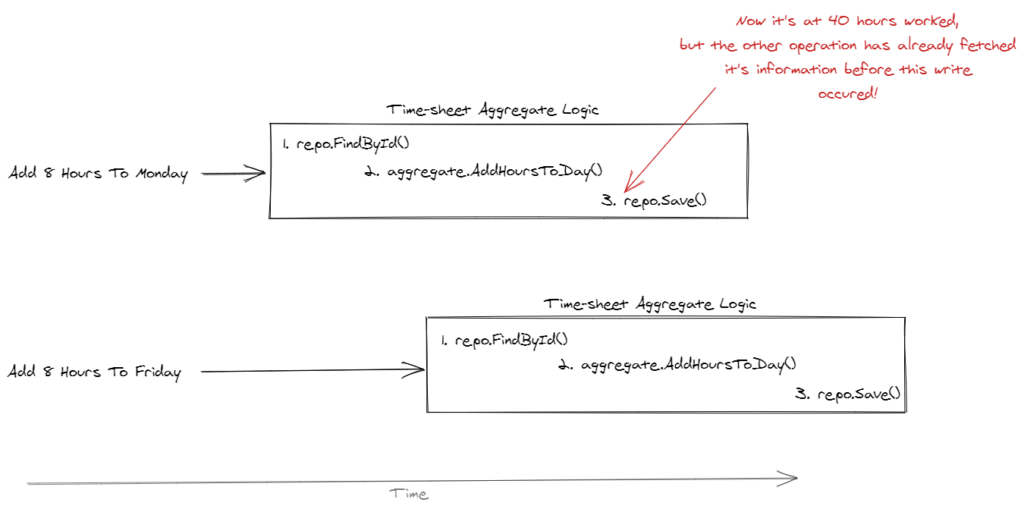
How do we solve this so our invariant of “time sheets cannot exceed 40 hours worked” is never broken?
Concurrency Controls
One of the most popular ways to solve this is by using concurrency controls. In other words, some way to block these concurrent writes to the database when the data is out of sync.
Pessimistic Concurrency
One way is to use pessimistic concurrency. This is when we lock the entire resource and only one operation is allowed access at any time.
Kinda like when you open Excel and now no one else on the network drive is allowed to modify it 😂.
But, this suffers from poor performance and is, in a way, naive in that we are just “brute force” locking everything.

Optimistic Concurrency
Optimistic concurrency is somewhat more intelligent and flexible. It also allows for some interesting failure modes too.
This works by allowing each operation to get the current version of the data store. It might be a relational database, document or event sourced. Doesn’t matter.
Then, the version is tested against the data store whenever the aggregate is being written back. If the version is out of sync (i.e. someone else has written to the store while this operation was processing), then we fail the operation.
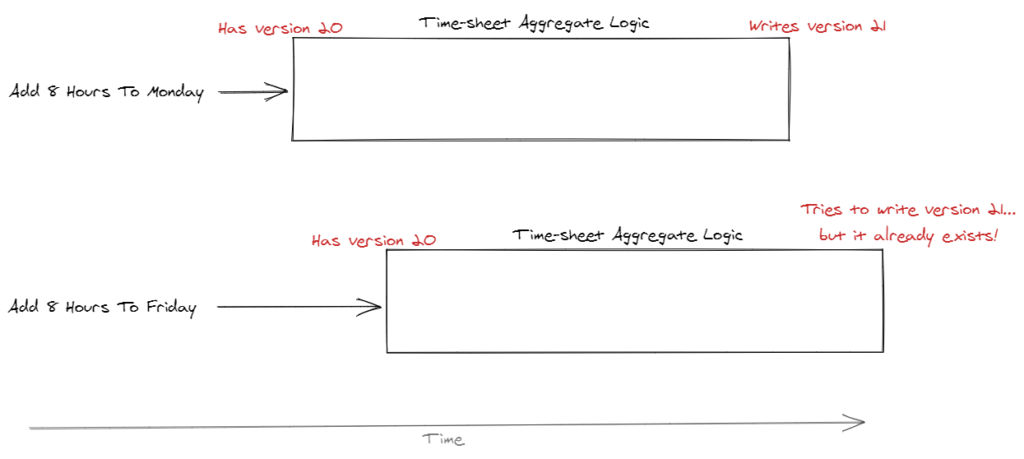
This allows for an interesting failure mode where the failed operation can just re-try. As long as its operation still makes sense given the updates in the data store.

How To Implement It?
Event store, for example, has this built-in.
One of the write methods in the .NET client, for example, looks like this:
Task<WriteResult> AppendToStreamAsync(string stream, long expectedVersion, params EventData[] events)The second parameter is where you tell the event store what version you expect to be at. If it’s not at that version, just like in the example above, then you’ll be told by the event store.
In relational databases, you might do something like:
UPDATE sometable T
SET something = @someDataParam
WHERE T.RowVersion = @expectedRowVersionParamDepending on your database engine, this will return how many rows were affected. If none were affected, then you know that the transaction “failed” in that another operation wrote to the data store before this operation could.
Next Article
Check out the next article relating to Domain-Driven Design and unit testing!
5 replies on “DDD Aggregates: Optimistic Concurrency”
[…] the next article in this series, we’ll look at the […]
Thanks for the helpful series, really enjoying them. Some small feedback on the UX, the illustrations you have are “content rich” and pretty central to the story telling of the post however the text is too small to read with the way it is inlined here.
If possible, it would be very helpful for larger screens to be able to click on the photo to have it open in model to “zoom in”.
Awesome – thanks for the helpful suggestions!
Hallo,
Thanks for your great article
My object GroupCluster { groupId, personId, dateFrom,dateTo}
I have to verify that mandant of group is equal to mandant of person , can i do it outside the aggregate ( domain service) or should i refer full person and full group in my aggregat “groupCluster”?
In my api i have always return all person data ( name, surname… simple 4 fields) , but my person will use in different usecases and is a Aggregat too.
Thanks
Without knowing other details about your domain I wouldn’t be able to answer that question. Some options might be:
– Use a domain service to grab data from other aggregates and make the decision
– If the data you need is actually in another domain or bounded context, then this might involve a distributed process (saga, process manager, etc.)
– This could be a sign of not storing the proper values in this particular aggregate
There are also other approaches which are to make the check asynchronously after the “groupCluster” has been persisted. If there’s a problem, then you can either undo the change, notify the user, or some other action. Whether this is a good way to solve the issue depends on the business requirements / invariants.