
It’s time to look at the idea of aggregates as a consistency boundary.
In my first article about aggregates, we looked at what an aggregate might look like. I intentionally kept it very simple and straightforward.
Aggregates are a pattern that can be used to model, design and build complex domain problems in a way that:
- Elegantly solves it
- Produces flexible & maintainable software
One of the facets around designing aggregates are what many call aggregate rules of thumb. In Vaughn Vernon’s book “Implementing Domain-Driven Design“, he highlights 4 rules of thumb to help drive the design of aggregates. Vaughn also highlights these rules in some articles he wrote based on his book’s content.
About Aggregates
In the original Domain-Driven Design book, Eric Evans makes these comments about what kind of problems aggregates solve:
Invariants need to be maintained that apply to closely related groups of objects, not just discrete objects.
Domain-Driven Design p. 125 (Kindle version)
What’s an invariant?
An invariant is a business rule that must always be consistent.
https://dddcommunity.org/wp-content/uploads/files/pdf_articles/Vernon_2011_1.pdf
In other words, we often have business rules in our applications that span multiple objects. How do we manage that?
The Aggregate Size Spectrum
I like to think of this problem as a spectrum:

And then, laying on top of this spectrum the two main issues that aggregates try to address: Consistency in relation to business rules & high-contention:

Example: Library Booking
Think of this in terms of a library.
What if a library had one massive book/volume that people could rent?
Only one person could book the entire collection of works of that library at a time.
This would be on the far right on the spectrum:
- That one person could cross-reference other material very quickly in one fell swoop (they have access to everything at one time!)
- If that person only wanted to read a small portion of the entire collection, no one else could rent the other books/parts that weren’t needed by the renter!
The opposite would be if books were rented out by the chapter. So, many people could rent (less contention), but cross-referencing material would be difficult and involve having to rent out many books over a period of time.
Now imagine all of this existed as objects in your software.
One massive object model would be consistent, but face contention issues.
Many tiny objects (not held together in some way) would face much less contention but would struggle to apply consistency when multiple users were trying to apply changes to the system.
Transactional Consistency
Think of a database transaction. When we commit a transaction to a database, we do it because all the data in question is only truly coherent together.

What if the code that updates the approval history crashed and we weren’t using a transaction? We now have an approved time-sheet but have lost the corresponding data for the time-sheet’s history.
We’ve got data corruption.
It’s not data corruption in the sense that the physical data is corrupted (like your hard-drive can’t even read the data).
This is logical data corruption.
You’ve got inconsistent data that doesn’t make logical sense when looking at the “big picture”.
Consistency Within Invariants
Let’s take these two ideas of consistency and invariants and blend them together.
Imagine you were working on time-tracking software.
Two different managers are adding time worked for an employee.

This would be fine since one manager is modifying a different day than the other. The implemented code will fetch each day individually, and they are stored as different database rows too. So no contention issues here.
Uh Oh…
What happens when we are asked to restrict the total amount worked for the entire time-sheet?

In this example, the two managers are each adding 8 hours to two different days. But the time-sheet is already at 32 hours and should not go over 40 hours (that’s our new business rule).
Right now, both cases will fetch from the database that the time-sheet has 32 hours left.
By the time the top operation finished actually adding the additional 8 hours worked, the other operation has already fetched the state of the time-sheet…32 hours worked.
What will happen is that both will succeed. And, we are left with 48 hours on a time-sheet! 😀
In this scenario, we’ve not created some kind of consistency boundary.
What If….
What if we added a boundary around the entire time-sheet and associated objects?
We could treat the entire time-sheet as the “gateway” to all operations that can occur to it or things “inside” of it.

Now, any operation on the time-sheet as a whole has to be applied through the aggregate.
Kinda like a bouncer.
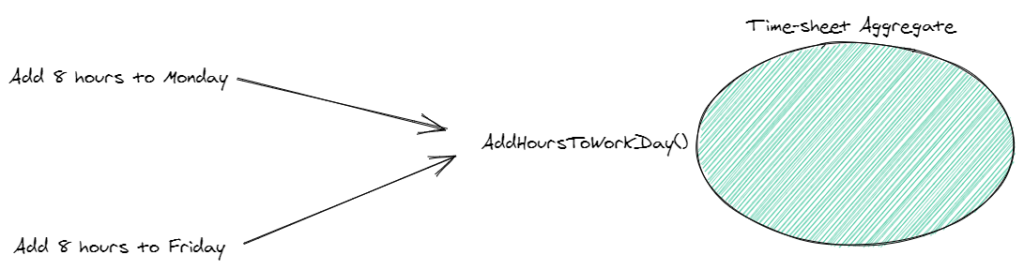
Now that we’ve added a consistency boundary around the entire time-sheet we can have control over what operations can be executed against it. Our logic is not split up throughout different parts of our system.
Note: Yes, there are still issues around contention and locking. We’ll cover that in another article.
Aggregate Rule Of Thumb #1: Model True Invariants As Consistency Boundaries
Now, with all that background laid out 😅…
Let’s look at the first aggregate rule of thumb:
Model true invariants as consistency boundaries.
Notice, this doesn’t say model your…
- Entities as consistency boundaries
- Fields as consistency boundaries
- Data as consistency boundaries
But, the focus is on invariants. Invariants should drive our aggregate design.
Let’s say that again.
Invariants should drive our aggregate design.
Did you get that?
Invariants should drive our aggregate design.
Invariant Driven-Design?
Remember in our example of the time-sheet that we started off with a model having individual days of a time-sheet as separate objects (and even database rows)?
Based on our invariants, there was no need to do anything else.
However, when we had a new invariant around keeping the entire time-sheet’s total worked hours restricted to no more than 40 hours, we were forced to change our model to accommodate this change.
That’s what this is all about.
You might look at two very similar businesses. Let’s say vehicle insurance online applications.
Should they be modelled the same? Well…. that depends.
Depends on what? On the invariants.
One business might not have sophisticated rules.
The other might have very strict rules.
This would affect how we design the software, and therefore the aggregate boundaries.
True Invariants
So, what about this true invariants business? What does that mean?
Vaughn Vernon tells us:
There are different kinds of consistency. One is transactional, which is considered immediate and atomic. There
https://dddcommunity.org/wp-content/uploads/files/pdf_articles/Vernon_2011_1.pdf
is also eventual consistency. When discussing invariants,
we are referring to transactional consistency.
So, true invariants are those business rules that are speaking of transactional consistency. In other words, a rule that doesn’t make sense to be “checked” later. That “check” or validation needs to happen at the moment some operation is attempted.
For example, imagine we are building a video game with two people fighting each other.
What would happen if your opponent’s health points dropped to 0. But, they didn’t die? Yet.
Maybe in a few seconds, the system would check, and then the opponent would die. Does that make sense? Nope.
True invariants are those that need to be kept consistent within the same transaction as the operation that relates to that rule.
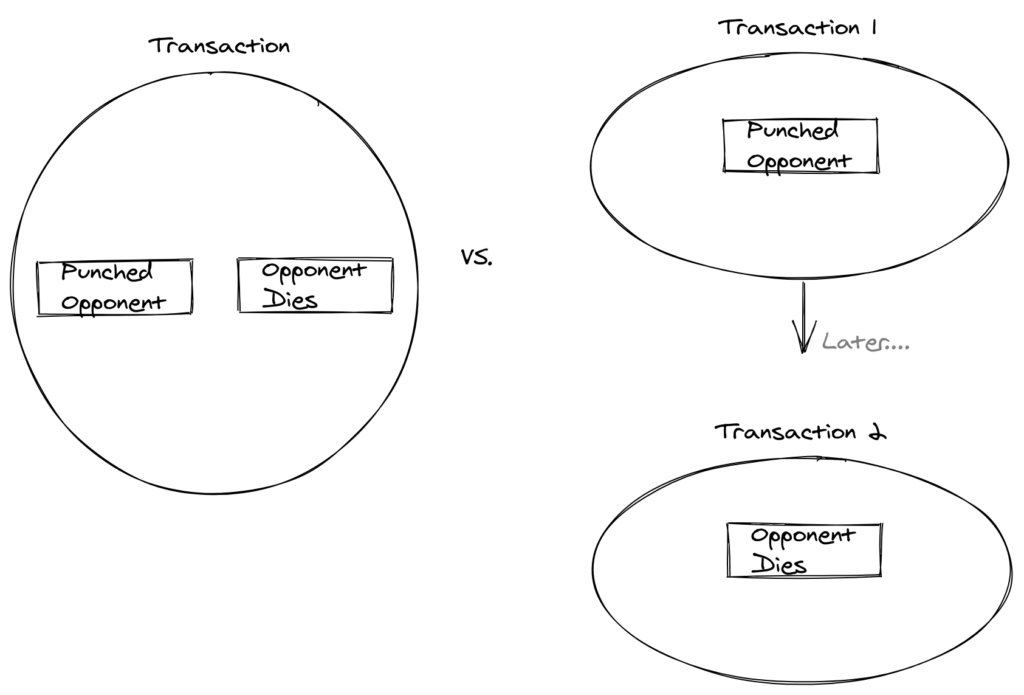
As Vaughn mentioned, there are business rules that can span aggregates. But those do not require immediate transactional consistency.
For example, what if a rule in an online insurance application was to ensure that the applicant’s credit score was “OK” enough to allow them to have insurance?
Would we need to check that at the same time that the applicant is submitting their application? Nope.
We could do that later on, and the system would make sense.
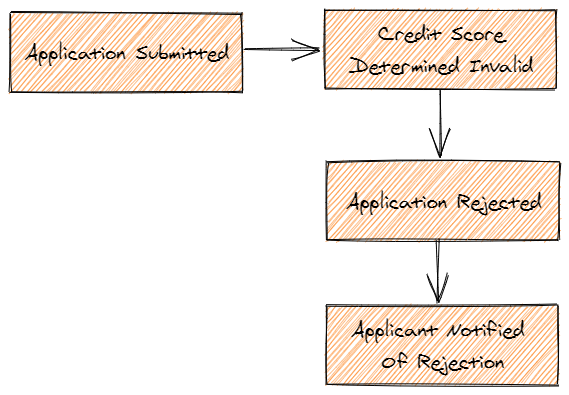
We would say that the insurance application is eventually consistent. At some point in the future, while we are “waiting” for the system to do stuff, we know that things will work out eventually.
It makes sense, as a business process, to have a submitted application that is “in process” of being approved (or rejected).
These would not be considered true invariants, in the transactional sense. Although, they are still important business rules.
Conclusion
We covered a lot of ground!
We took another look at what aggregates are and why they are needed.
Then we examined some examples that expose problems that aggregates can help us solve.
And then we looked at the 1st rule of thumb: model true invariants as consistency boundaries.
Take some time and think about your system. What are true invariants in it? Which ones aren’t? What would happen if you modelled your objects according to relevant invariants?
Next Article
In the next article in this series, we’ll look at the question:
“What happens when multiple users of your system try to operate on the same piece at the “same” time? Who wins? Who loses?”
7 replies on “DDD Aggregates: Consistency Boundary”
Just a tiny nitpick. Shouldn’t there be a verb in CreditScoreInvalid? (as example CreditScoreDeterminedInvalid etc)
I suppose if I am modeling that explicitly as events, then it does seem more proper for me to be consistent eh.
Consisder that example eventually consistent 😋
[…] looked at the first aggregate rule of thumb in the previous article about Domain-Driven Design aggregates. What I didn’t cover was how to deal with collaborative […]
[…] Modelling transactions to ensure consistency for all the data in one aggregate? […]
[…] people start talking about consistency boundaries, transactional consistency, eventual consistency, aggregate boundaries, invariants, aggregate roots, […]
Great work on breaking down aggregates, it has always been a difficult one for me to crack.
How do you adapt aggregates to systems that sit across different databases to achieve consistency. Lets say you have an system that needs to interact with a different system to fulfill a particular business requirement. For instance, using your TimeSheet example. If after a timesheet is entered we need to increase the employees salary so that when the automated renumeration system runs, it would pay the employee the right amount of money. How would you model this?
Thanks!
So I don’t think you would ever tie one aggregate to more than one database. The #1 purpose of an aggregate is to get transactional consistency between everything that the aggregate “contains” (e.g. the database tables or document that it commits to when writing).
If you have a situation where you need some kind of transactional consistency for data that’s held in different databases, then there are two thoughts that come to mind:
– Use something like a saga or process manager (which turns this transaction into more of a business workflow)
– Maybe that data should belong in the same database? (has big implication if this is true!)
In your example, you’re thinking of two completely separate systems. So you’d want to take the saga/process manager approach. The bottom line is that you can’t achieve ACID-like consistency guarantees, but you can have a longer running business transaction/workflow using this approach.
In this scenario, each system would have their own aggregates (so possibly 2 or more aggregates in total for what you’ve described).
Does that help?