
How should you structure your .NET solutions and applications?
Should you use microservices or build a monolith?
The answer is not so straightforward and will most definitely be best answered with an “it depends”!
P.S. This article is part of 2022’s csadvent 🙂.
Decisions…
There are many different ways to implement separate modules in a given .NET system or solution:
- You can build separate .NET projects that get combined at runtime into a working solution.
- You can publish modules in your systems as separate NuGet packages and then combine them via a main entry point project/process.
- You could opt to use a monolithic structure using clean architecture (I’ve written why I’m not so fond of this approach).
- A modular monolith using feature folders / vertical slices is an option.
There’s another important consideration: how you deploy is a separate decision:
- If you have a modular monolith, you could just deploy the entire thing to a server.
- You might load balance a monolith running on multiple servers.
- What if you deployed multiple instances of a monolith but dedicated each server to only handle certain HTTP routes?
- Many microservices could be deployed to one server?
- Your microservices could be deployed to separate nodes using something like Kubernetes?
There are so many choices!
Another consideration in all of this is around how your modules communicate with each other. This is also a separate decision:
- In-memory messaging? (Might use in-memory queues or event broadcasting)
- API requests between modules?
- Asynchronous messaging?
Alright 😅. What about your database storage?
- One database per microservice?
- Multiple databases per microservice?
- Shared database between sets of microservices?
- Shared database with schema separation?
- One database to rule them all?

There’s no one magical decision that will make your .NET solutions structured well. There is a myriad of choices you make that affect how easy your solutions are to deploy, what the experience of developing in them is, how efficient or performant they are, etc.
In this article, we’ll look at:
- Why you might want to take a given approach
- What the general trade-offs are
- Some examples/scenarios of how to implement some of these
Think Of Architectural Decisions As A Spectrum
Architectural decisions can be combined in many different ways. Each combination has its own set of advantages and disadvantages.
For example, you might have a monolith that is logically split into separate modules & uses a separate database per module.
On the other hand, you might have an architecture with many microservices that share the same database (but might be segregated into separate schemas).
This last example might sound silly, but this kind of architecture may be optimizing for a combination of system attributes like:
- Very explicit boundaries
- Optimizing for development speed
- Trying to avoid code conflicts between teams
- Minimizing the cost of running multiple databases. (e.g. This organization may not yet be ready to dish out the 💲 for more databases)
So, for each of these types of architectural decisions you can place them on a spectrum of sorts:


Deployment to a single server is usually much more cost-effective and simple to operate than many services running on Kubernetes. Yet, Kubernetes can be warranted if you need the ability to scale your services independently at runtime 🤷♂️.
Note: It’s worth mentioning that legacy systems which are being updated with more modern development techniques and approaches may have a “weird” set of architectural decisions. This is where ADRs come in handy!
4+1 Architectural View Model
One way to view the relationship between these various kinds of architectural decisions is the 4+1 architectural view model.
First, head over to Derek Comartin’s article on this architecture framework, then come back.
Okay, welcome back.
The Original 4+1 Paper
The original 4+1 paper has a specific section that highlights the relationship between the logical and development views. It points out that how we structure our code may not be exactly a one-to-one match against our logical components:
Additional constraints must be considered for the definition of subsystems, such as team organization, expected magnitude of code (typically 5K to 20K SLOC per subsystem), degree of expected reuse and commonality, and strict layering principles (visibility issues), release policy and configuration management. Therefore we usually end up with a view that does not have a one to one correspondence with the logical view.
https://www.cs.ubc.ca/~gregor/teaching/papers/4+1view-architecture.pdf
Code structure, deployment strategy, logical components & how many processes are running your system are all separate concerns. These may or may not overlap due to desired trade-offs for your organization and your specific solution.
An Example: Clean Architecture
So, I have gripes with the Clean Architecture approach. This is mainly to do with how developers often conflate the principles of clean architecture to represent exactly how you should structure your codebase. This concern is really that there’s some conflation going on.
The 4+1 architectural view model can help to sort this out.
You don’t need to create a folder structure that maps to the direct logical concepts in the Clean Architecture approach.
In other words, the 4+1 development view (e.g. your file and folder structure) can be different than the logical view (e.g. the flow of dependencies between the classes and interfaces).
A “Better” Clean Architecture Implementation Guided By The 4+1 Model
Imagine that you have a feature folder like ShoppingCart. Inside that folder, you have application services, data access, domain logic, etc. Your data access might be accessed via an interface (why not also found in the same folder?).
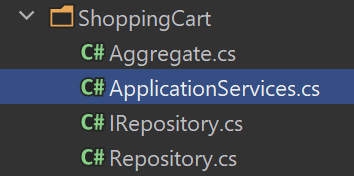
Web controllers, for example, would interact with the ApplicationServices class. You can unit-test both Aggregate & ApplicationServicesIRepository. But, this doesn’t mean you need separate .NET projects for each of these classes.
How clean architecture is usually present on slides during conference presentations is not how you need to physically structure your code. It’s the logical coupling and the flow of data that matters. You don’t need all the extra folders and projects.
Exploring Different Architectural Decisions
Now that I’ve had a chance to vent about clean architecture 😋, let’s look at a few mock situations to show how you might choose to structure a .NET solution using some of these kinds of architectural decisions.
Your Mission – Should You Chose It…
Your fictitious organization needs you to build a new software product against certain limiting factors or desired system attributes.
You’ve been tasked with building an all-new system: a project management Saas for arborists (e.g. tree maintenance).
As the CTO and only developer of this new start-up, you really don’t have many requirements about how you ought to build the system. You have been told to get an MVP out the door as quickly as possible.
Monolith With Typical Clean Architecture Approach
Knowing that a monolith is probably the quickest way to build an MVP and get started, you decide to go this route.
You’ll only need one database right now too. Nothing fancy.
However, you’ve read about clean architecture and how it can “future-proof” your system and make your code decoupled.
You decide to give the typical clean architecture structure a try:
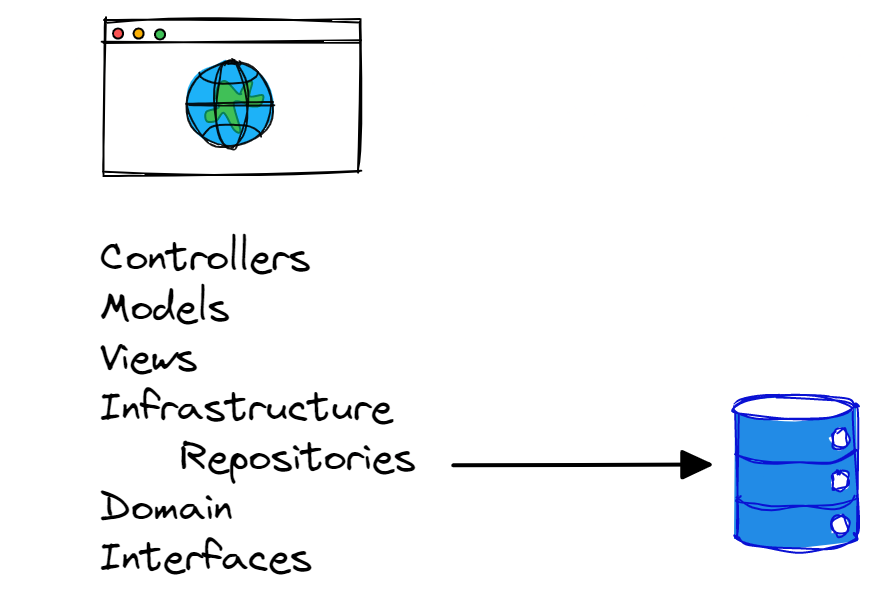
Sometimes, this structure looks more like this:
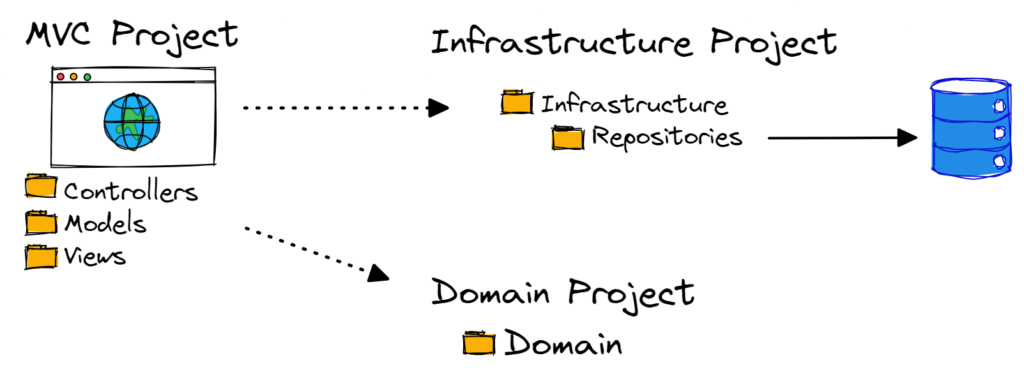
After you get the first iteration of the product out into production, you end up hiring a couple of developers.
Over time, there are some issues that your team discovers with the solution:
- When you need to work on feature X, it’s hard to find where that feature lives.
- The web framework’s convention and structure direct your application’s structure. You have a growing sense that this is a muddling of concerns.
- One of the new developers has asked about using Razor Pages instead of MVC. But how can you start using an alternate approach to building your application/UI layer?
- Do you add new folders like
/RazorPages,/ApiControllers, etc.?
- Do you add new folders like
- How can you quickly figure out that feature X uses MVC controllers, razor pages or API controllers?
Monolith With Feature Folders
Because of these issues, your team does some more reading. You find that a good next step is to start splitting your folder structure into more business or domain-focused areas.
This new structure is at first glance very similar to the one above – except your business capabilities or “features” are the top-level pieces of your structure.
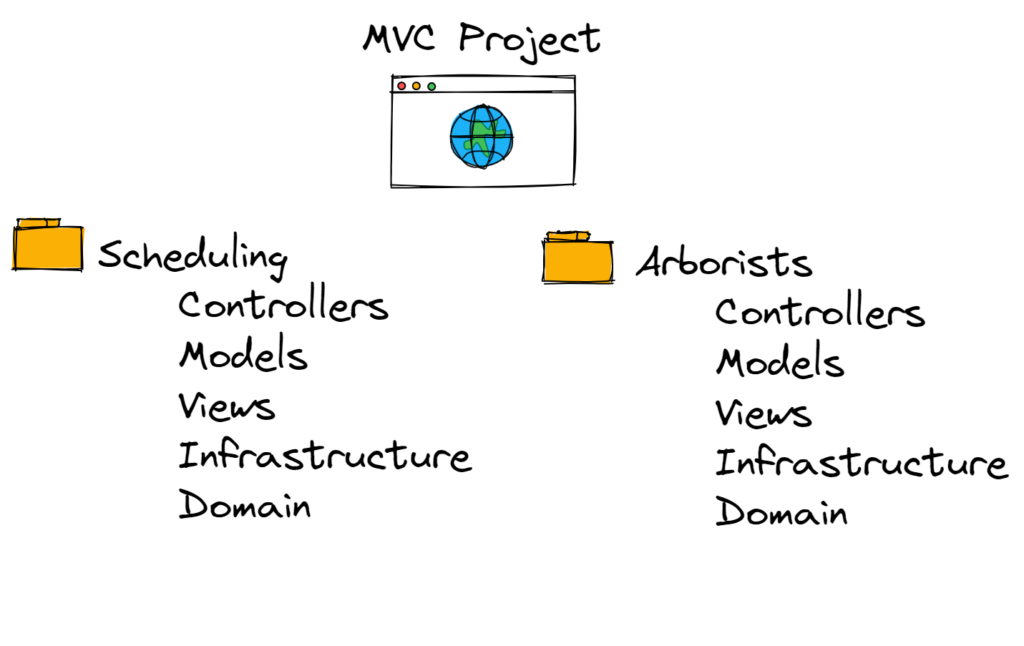
This structure improves your ability to find existing features and figure out where to start working on a new one. It also gently prods you in the direction of thinking more about your software in relation to specific features or products in your business instead of technological aspects (like interfaces, repositories, controllers, “utilities”, etc.).
In reading up though, you find that there are still some downsides to this approach:
- You’ve still allowed the web framework to somewhat drive the folder structure of your application overall.
- You’ve forced a “one architecture to rule them all” approach to all your products and features. What if one feature is better fitted for a CRUD-based approach, but another is more well suited to a long-running process using asynchronous messages?
Monolith With Vertical Slices
You’ve added more developers to your organization – now you have two general teams of developers. But, they keep stepping on each other’s toes – merge conflicts are commonplace!
One day you come across Derek Comartin’s video on YouTube about vertical slices.
This approach makes one subtle yet massive change to how you think about designing and developing your monolithic solutions. Instead of applying one way of structuring your features, what if you allowed the needs of each feature or “slice” to be flexible? (Oh – and stop putting related pieces of feature code in separate projects too…)
- Perhaps one feature warrants using a clean architecture approach?
- Another might be better suited to a really simple CRUD approach using transaction scripts.
- One might require its business process to be split into separate asynchronous pieces of work that eventually come together to complete a given body of work.
Under this approach, your system might look something like this:
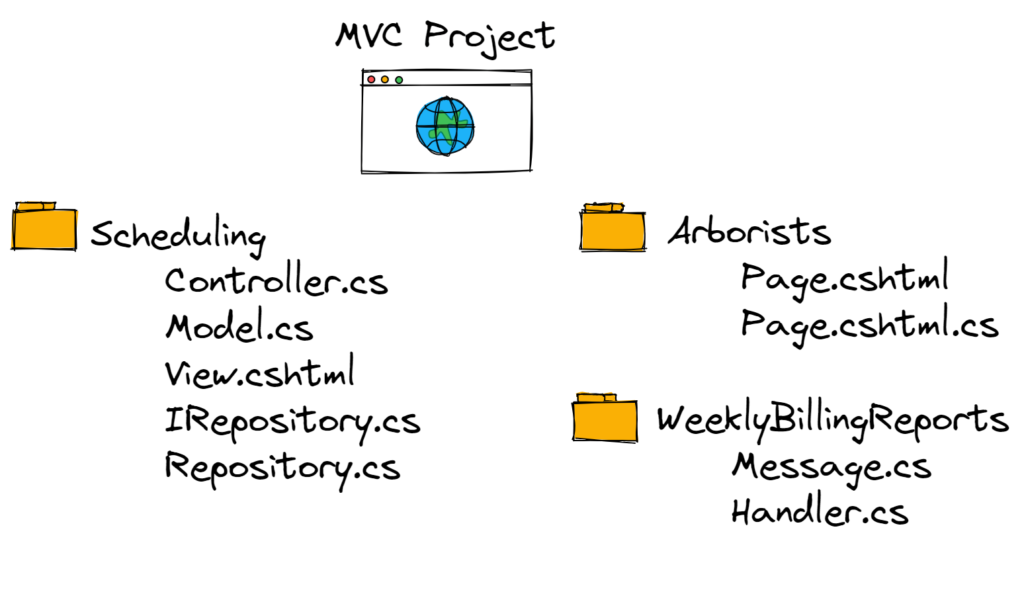
Some questions that might come up with this approach are:
- What if I have to share functionality or logic between features?
- How do I determine what approach a given business capability should use?
- Should I still use one shared database for this approach?
Database Considerations
At this point, you see that you aren’t that far from tearing specific “slices” out into their own .NET project/process.
Some might call these separate processes “microservices”. But I digress.
Let’s look at the question about shared databases.
There’s nothing wrong with using a shared database when running on a monolith. It might even be optimal in terms of operation complexity, cost savings, local development experience, etc.
That being said, I believe that if you are going to take a more “grown-up” approach to structure your applications then you should extend that to your database structure too.
Coupling
For example, when using a monolithic vertical slices approach, I would also opt to segment the data for each feature folder into its own schema.
If you find that there are features that need to perform SQL JOINs on tables owned by another feature, then there might be a need to reconsider how you allow features to communicate with each other (instead of reaching into the database and querying directly). This database coupling is one of the strongest and most insidious forms you can introduce between your features.
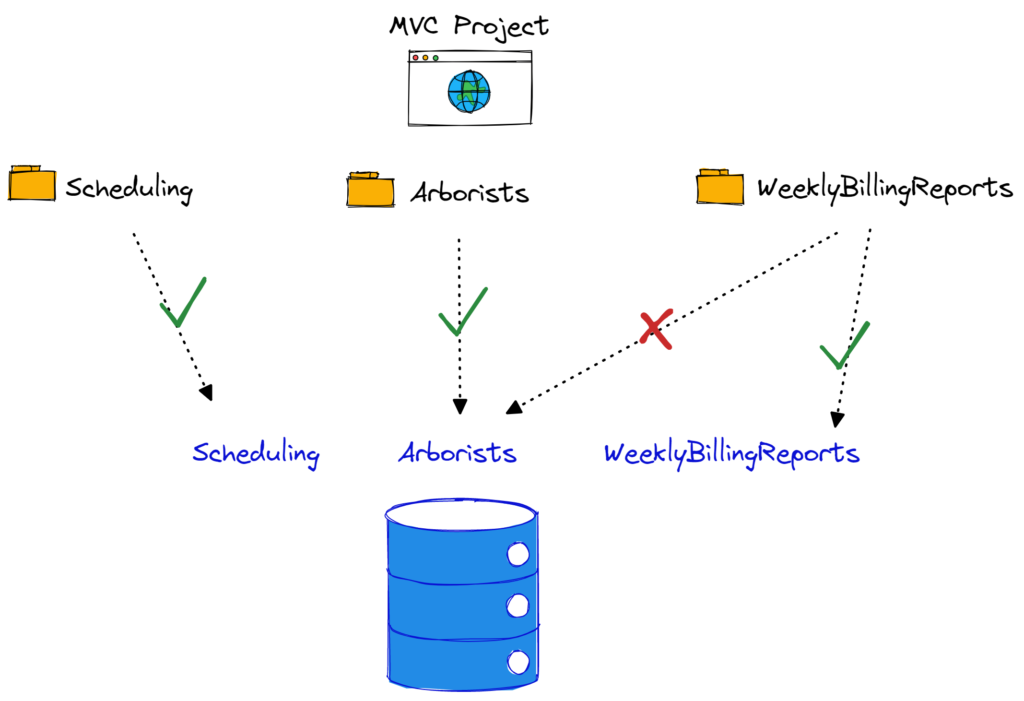
And that’s the crux of why you would want to structure your .NET solutions this way: to reduce coupling and increase cohesion.
In other words, you don’t want changing one feature to inadvertently break another feature (that signals coupling). Changing code for one feature should require that you don’t have to find files all over the place. All the files you need should, ideally, be inside of the vertical slice or feature folder for that given business capability.
Services
Your organization is growing. The product is doing well.
But, you’ve come to find that the WeeklyBillingReports feature requires a lot of resources. It has affected the overall performance of the solution.
One approach would be to split this feature off as its own process. You might take the vertical slice and move it into a separate .NET project.
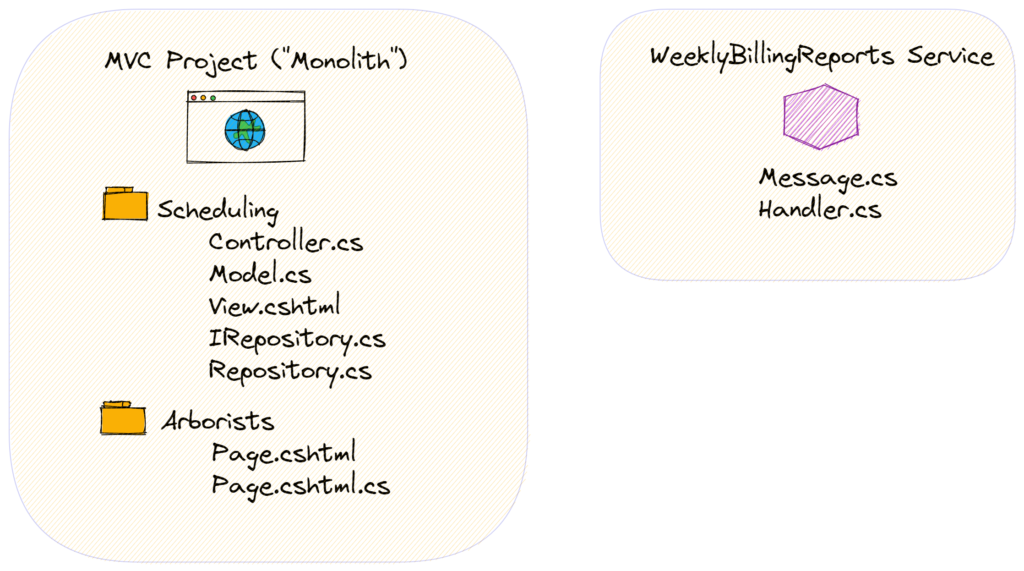
Both of these projects might use the same database – especially if both projects are owned by the same team.
The question then comes up: when should I take the schema WeeklyBillingReports and put it into a dedicated database that only this service can access?
A few reasons might apply given your situation:
- Performance: A dedicated database instance might just perform better for this capability. This may be forced upon you by specific SLAs or just an overall desire for this feature to not affect the monolith’s database (or the other way around).
- Data Isolation: You just don’t want other developers to even have the ability to make the mistake of querying this feature’s schema directly.
- Team Autonomy: This service is going to be owned by a new or existing team. Keeping this service’s data isolated is a critical piece of making the team autonomous.
Microservices
Then, one of the most demented ideas you’ve ever had pops into your mind: microservices.
A question even the wisest of our sages cannot sufficiently answer: “what is a microservice?”
Given the structure above, assuming WeeklyBillingReports has it’s own dedicated database – you might call this a microservice.
Does it depend on how much code is in the .NET project in order to call it a microservice? Nobody really knows… 😋
Front End Considerations
In this fictitious solution, we’ve assumed that all of your user interfaces were either MVC views or Razor Pages. What if you wanted to use a single-page application with Angular, React or something else?
Using micro-frontends is one option. UI composition or view-model composition is another option in your tool belt.
Or, you could just decide on a feature-by-feature basis:
What if the Arborists feature, which is mostly CRUD, was just plain old Razor Pages?
However, the Scheduling feature is pretty complex on the front end. Maybe a SPA dedicated to this feature will make sense?
How you share styles and JavaScript is a legit concern. But, it’s doable. This might be the point where you need to introduce a design system as Slack did.
The End
You’ve seen that structuring and designing your .NET solutions can vary quite a bit. The main bit that you should take away from this article is that there is variability – but some general ideas that you should seek to keep in mind:
- Keep files that change together…. together. Preferably in the same folder/slice.
- Clean architecture doesn’t mean you need 6 different .NET projects to get started.
- Features should not touch the database/schema/tables of another feature.
- If you use vertical slices it becomes very easy to extract a slice into a dedicated service if/when needed.
- Do you really need all those microservices? Try waiting until you’re forced to split things up.
- Sometimes, your organization’s structure might look “weird” because of some specific combination of constraints like cost, operation overhead, developer experience, technology age, reliability, documentation, compatibility with existing technologies you use, security robustness, etc. That’s okay – just be aware of what those reasons are and share those reasons with your team.
8 replies on “.NET Architecture: How To Structure Your Solutions”
Excellent post accompanied with great sketches!
Thanks
Thanks for the kind words!
I liked the way you wrote the piece. Instead of prescribing The Way (singular), you’ve described The Options (plural). Which is a good food for thoughts and invites further discussions and considerations.
Great! Thanks for the kind words. Glad you thought the piece was worth thinking over / checking out. 😀
Nice article. very clear and easy to read. But I do think your article is favouring one type over another when you get to the end. So here’s some thoughts on the opposite that might help others in a similar situation to me. where project splitting works perfectly fine and is even a benefit over feature splitting.
I’ve recently been part of team discussions around grouping classes into a single API project split by feature, rather than have multiple (Application, Domain, Infrastructure) projects.
My argument for a split like this was for composability in our domain space. Our business domain isn’t feature split like your shopping cart or scheduling examples. There is a clear domain language split with bounded contexts and aggregate boundaries. So if we attempt to split based on features we will end up with lots of duplication and having kind of the same “thing” done in multiple places but slightly different. I’ve seen this happen before where there are 3 different ways of interacting with a “thing” because the feature required those very slight differences. You end up with lots of accidental coupling that isn’t obvious.
Instead we build Modules that do one thing well and follow CUPID properties. We have a clear domain split that’s consistent in each project using folder names. So if you are working in a specific domain it’s clear the area you should be looking in, and if you are new you can see the domains and understand the business as a whole rather than just one feature. This allows us to compose the modules (objects and classes), or rather use the responses from those modules to build things like views and composite objects, but only where they are appropriate in the Interface. This is where Clean Architecture has really helped with the clear boundaries. Our domain is clear, easy to follow and use in any way possible. We have been able to build internal APIs for our web portal, public APIs for clients to consume, Serverless functions for a message based ETL process, and in the future whatever else we may need to. I think if we feature split our code we wouldn’t have been able to do all this.
We did however follow what you are saying in our web portal APIs because feature splitting makes sense here (e.g. routes, controllers, models, interfaces), but grouping it all together down to the repository and restricting ourselves to only an API would have been a bad move and harder to scale without refactoring.
Just to be clear, I’m not saying I disagree with your article. I just wanted to give an example of when it’s ok to have a project split and follow clean architecture. It’s just as easy to split modules and compose them together as it is to split vertical slices. You just need to consider the bounded contexts
A question could be… is Scheduling a feature or a module? The module would control everything to do with scheduling. It could be made of of the individual features on the outer layer (e.g. API) but a module that controls working with those scheduling objects is a sharable component.
So for me the answer is that it depends, and both styles can be used together. Sorry for the long reply!
Very nicely summed up with simple and easy to understand concept visualization!!
Glad you found the article useful!
[…] written about this a few times (1, 2, 3). I’m not the biggest fan of clean architecture. I think many of the principles found […]