
Today we’re going to look at taking an “existing” .NET application and add a new process/component that imports a user’s GitHub repository data and keeps it up-to-date.
We’ll look at how to design the process in relation to our web application, how to use Coravel to easily add background scheduling, and more.
Show Me The Code!
First thing’s first – here’s the repository with all the code!
Importing GitHub Data Into Our App
We have an existing web application. It looks something like:
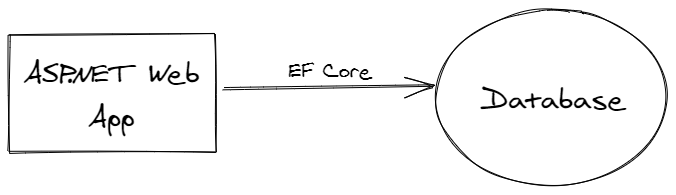
In the sample code, this is represented by the Web Project.
We want our application to display a list of GitHub repositories for a given user.
We might want to fetch data from the GitHub API every X minutes, match those records up with what already exists in our application and persist those updates and additions.
Questions that come up at this point might be:
- Do we have an SLA for how stale our system’s data ought to be?
- Do we forsee importing data for multiple users in the future?
For this sample, we’ll stick to one user and say that data should be up-to-date within a few minutes.
Designing The Components
So then, the logic might look something like this:
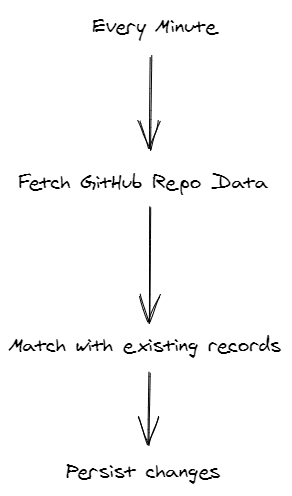
Now, we need to think about how each of those operations or steps could be implemented.
Scheduling
Scheduling is the first problem. Today, we’re going to use Coravel’s .NET job scheduler. This will allow us to easily configure a job to do the “work” every minute, for example.
The code for this part in the sample looks like this:
s.Schedule<ImportGitHubReposFromAPI>()
.EveryThirtySeconds()
.PreventOverlapping(nameof(ImportGitHubReposFromAPI));We are scheduling a Coravel invocable to run every 30 seconds in this example.
PreventOverlapping prevents Coravel from spinning up another instance of that job until it finishes – there will only ever be one active instance running. This prevents us from spamming our DB, the GitHub API, getting weird concurrency issues, etc.
API Requests With HTTPClientFactory
Next, we’re going to have to get data from the GitHub API!
In modern .NET applications, the most maintainable and performant way to do this is to leverage the built-in HTTP utilities.
HTTPClientFactory is what we need.
It helps us configure things like the base URL, headers, etc. once.
services
.AddHttpClient("GitHubRepoImport",
c =>
{
c.BaseAddress = new System.Uri($"https://api.github.com/users/{gitHubUser}/repos");
c.DefaultRequestHeaders.Add("Accept", "application/vnd.github.v3+json");
c.DefaultRequestHeaders.Add("User-Agent", "GitHubImporter");
});Then, our invocable class will receive the client via dependency injection:
private readonly HttpClient _http;
public ImportGitHubReposFromAPI(IHttpClientFactory factory
)
{
this._http = factory.CreateClient("GitHubRepoImport");
}Match Existing Records And Persist
Next, we need to take our results from the GitHub API and compare them against our current data source and store them.
You can see the code that implements this part in the sample repository here.
Architectural Concerns
The simplest way to do all this would be to build one job/class that does all this work.
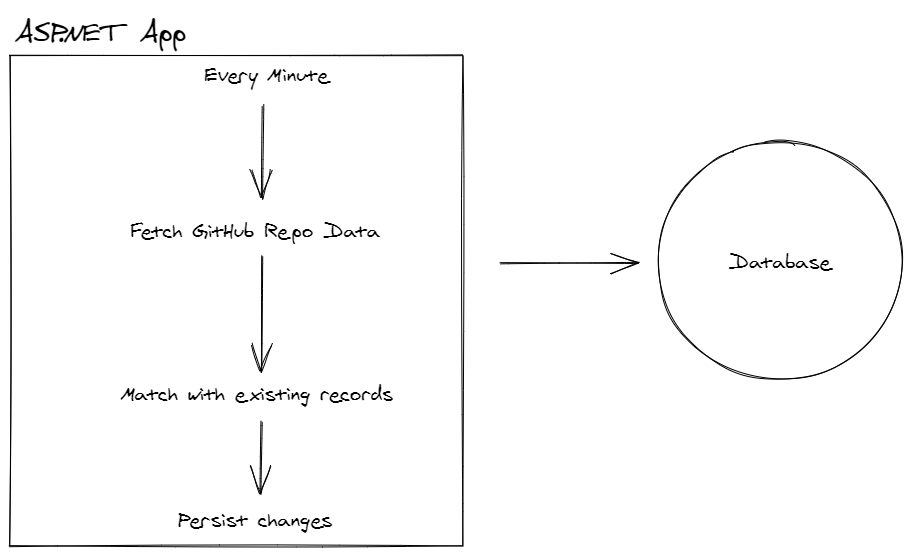
Some other considerations might be:
- What if we will want to move this to another process?
- What if we eventually are storing the data to multiple data stores?
- What if we are already trying to build our system in a decoupled kind of way?
One approach, the one I took in the sample repo, is to decouple the logical components by introducing an interface between the Web project and a new GitHubImporter project.
The interface/contract exists in a Shared project.
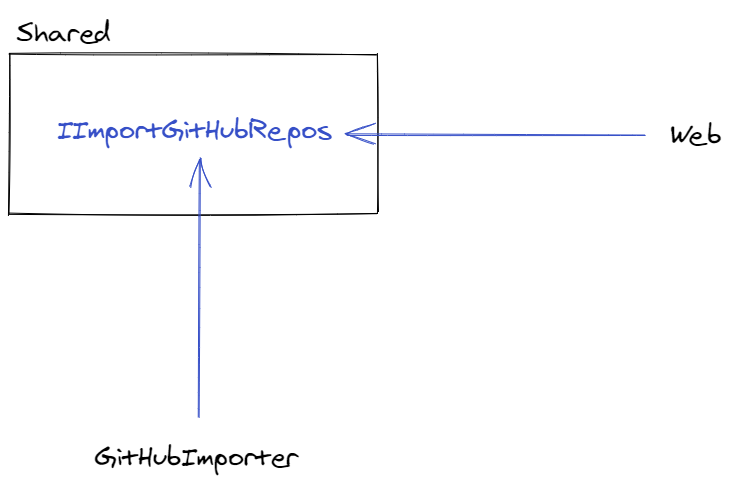
The GitHubImporter project is responsible for managing the job scheduling, API fetching and data preparation.
Once it has all the data in a clean format, as defined by a shared DTO, it calls into the IImportGitHubRepos interface to complete the process.
The Web project implements that interface. It’s responsible for matching the imported records to any existing records in the database.
By decoupling these we can keep changes related to each responsibility fairly isolated. It abstracts details away from us that can help with code legibility and future maintainability (we could deploy these projects as NuGet packages, for example).
For example, the Web project’s Startup class hooks into the GitHubImporter like this:
public void ConfigureServices(IServiceCollection services)
{
services.AddGitHubImporterService("jamesmh");
}
public void Configure(IApplicationBuilder app)
{
app.UseGitHubImporterService();
}Under the covers, Coravel is using a HostedService which makes it easy to build these kinds of repetitive background jobs and hook into existing .NET web applications.
Derek Comartin has a great article about how to design .NET solutions using this type of approach in more complex scenarios.
Again, you can dig into the sample more if you enjoyed this 👍.